Software engineering challenges in MLOps

Introduction
For the last few months, I have been involved in work expanding the frontier of understanding software engineering problems associated in the operational aspects of Machine Learning systems.
I did not have any background in Machine Learning or its ecosystem.
Before starting this assignment, I thought the problem space for operational aspects of Machine Learning was well understood by the professionals working in that area, and there are standard ways of addressing common problems.
Soon, I realised that was not the case, and a lot more work needs to be done to make it work for any particular organisation.
However, I was another step behind in this journey. In software engineering, the problem is never only the technology; a large chunk of complexity comes from understanding the business problem, problem space, boundaries, tradeoffs and domain knowledge.
And I found myself lacking all of it in these uncharted waters. Hence, I invested significant time trying to understand the segments of the Machine learning ecosystem. And how it is different from the usual software engineering challenges.
In this article, I am trying to explain what I have learned. I found myself in a boat to the world of Machine Learning Operations, trying to find my feet. Buckle up; we are going to take a ride to the adventurous world of Machine Learning Operations.
Terminology
Machine Learning is full of nomenclature. Hence, first, I would like to give the contextual meaning of the following words. Some of those have well-known meanings in software engineering and can be interpreted entirely differently if you do not have a Machine Learning background.
ML Practitioner: A person involved in a Machine Learning system in a functional capacity.
ML Model: A file that has been trained to recognise certain types of patterns of set of data.
Data Lake: A data lake is a central location that holds a large amount of data in its raw format.
Feature : Model features are the inputs that machine learning models use for training and inference to make predictions.
From here onwards, I will discuss the main components I have learned about the operational aspects of Machine Learning. And this is not ordered in a way a Machine Learning Engineer would layout it for you. The following layout is the perspective of a software engineer trying to understand the problem space and domain.
MLOps
Since the inception of micro-services (Building large-scale software systems in a modular fashion, each service has its well-defined boundary), the software industry identified the value of keeping the operational aspects proximate to the development.
DevOps is the word we use to identify this cultural shift of breaking down the barriers between software development teams and teams who run the application in a production environment.
They become one team and grow empathy towards each other. As a result, they start straightforward ways of communicating and come to a common understanding of what the software should look like when it is production worthy.
MLOps embrace this working model of DevOps and extend it with machine learning-specific components. The following diagram shows the difference between these two operating models. This will make it easy for a person with only a software engineering background to understand the differences and additional components.

From here onwards, I will dive deep into MLOps component and expand on the software engineering challenge on that topic. I will not discuss the common segments for both DevOps and MLOps as it defeats the purpose of this article but focus more on additional complexity brought into the picture by machine learning systems.
Development
Developing software is challenging. Machine learning brings another layer of complexity on top of that.
Traditional software development starts with identifying the problem, defining requirements, designing solution(s) iteratively, and finally coming to development iteratively.
Unlike traditional software development, machine learning requires additional steps to get the model development and training. The data used for the ML model training needs to be available for ML practitioners.
Data extraction and storage
It could be analytics data from your online shopping portal or transaction data from your banking application. These data collection points need to integrate with your primary ML data sources.
Engineering challenge
- Extract data and move it to data storage so ML practitioners can access it.
- Usually, organisation call this a data lake. A data lake holds a large amount of data in its raw format.
- Implement necessary authentication and authorisation to access data.
- Ensure personally identifiable data (PII) is not leaking and comply with data protection standards like GDPR while enabling business opportunities and innovation through data.
Possible solutions
- Building a data lake and providing security controls and access APIs are not trivial tasks; it takes considerable effort to make the necessary abstraction over an existing object store like AWS S3.
- The other alternative is to buy a data lake solution from a vendor and implement it on your cloud infrastructure.
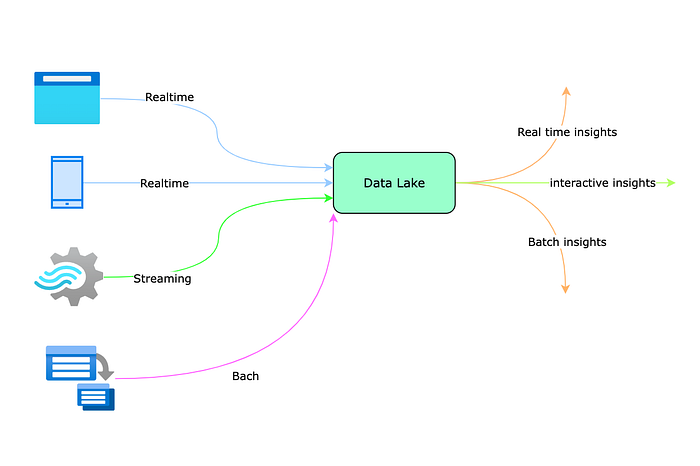
Data Analysis and Data Preparation:
Once the extraction is completed, we have raw data in a data lake. The next step is to identify the characteristics of the data. ML practitioners use various graphs and data visualisation tools to identify the data schema and characteristics.
Once data passes the analysis phase, the next step is to cleanse the data and prepare the data set to be used in model training and testing. Making those tools available to ML practitioners is another software engineering challenge.
Feature engineering:
Model features are the inputs that machine learning models use for training and inference to make predictions. The Model accuracy heavily depends on the quality of these features.
Feature engineering is the mechanism to derive new variables about data using the available data. Let’s take an example of a fraud detection model that uses a transaction data stream.
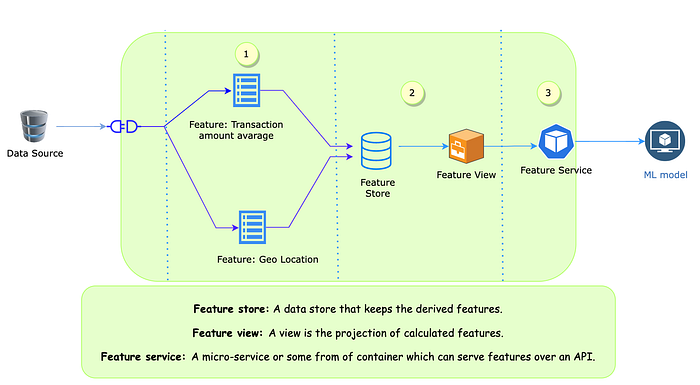
Step 1: Define and create features
In this step, we need to connect the data source to a transformation logic and create the definitions of the features.
Step 2: Derive, store and create views for the features.
Step two is storing derived features based on the definition and creating a curated view of the features.
Step 3: Wrap these feature views as API
Create an API layer that can serve these feature views to real-time and non-real-time models.
The combinations of steps 1 & 2 are zoomed in the following diagram.
It shows how transaction data derive features from applying transformation logic to feed into the fraud detection model.

If you look closely, you will see a set of data pipelines moving, transforming data from one form to another and serving it via API. All these segments require domain knowledge of the problem space and skill set for careful software engineering.
Engineering Challenges
- Build interfaces and connectors capable of consuming data from various types of data sources.
- Monitor, maintain, and validate the feature definitions with data drifts.
- Running feature services in the production environment.
Possible solutions
- There are feature store solutions from various vendors that offer most of the functionalities. However, careful evaluation should be done by the MLOps teams before selecting one, as this is an emerging area in the solutions that may not fulfils your organisation’s needs.
- Cloud providers like AWS provide feature stores as part of ML offerings. AWS Sagemaker feature store is a fully managed service.
- Maintain feature store using data pipelines and batch jobs; once again, the effort would be high.
Continuous Integration, Continuous Deployment and Continuous Training
Continuous integration
Continuous integration is the practice of integrating multiple code changes into a shared code base while continuously testing the software package.
In the context of DevOps, this software package includes business logic, data transformation, error handling, etc.
However, when it comes to MLOps, the baggage gets more extensive and complex; it includes validating input data to the model and validating the data schema.
- Model code and feature code are both in the source control system with semantic versioning.
- Validate the features against a pre-defined benchmark for numerical characteristics of the data.
- Each change to the model should re-validate the functionality via automated data accuracy tests and module accuracy tests.
- Store and fetch correct versions of the model artifact with its training data set.
- Test and validate not supporting steps such as dependency installation, feature definition logic, and feature serving components.
The above list of additional tasks requires extra engineering effort to glue the pipeline. There are several tools in the MLOps ecosystem to help this integration happens.
Continuous delivery
In DevOps context, at the point of delivery, the software package is verified with unit and integration test cases, passes the acceptance criteria, and is ready to be deployed to the production or intermediate environment.
However, in MLOps it is a bit tricky as a model artifact is not the only artifact we need.
There should be a few other things;
- A compatible docker image or computing system can support the model’s runtime environment.
- The underlying infrastructure should have enough memory, computing power, and GPU acceleration.
- Ability to do blue/green deployment and feature flagging.
- Ability to bring model and deployment infrastructure live.
Continuous Training
Continuous training is a new and extra segment unique to the MLOps.
Continuous training goes hand-in-hand with model monitoring which we will discuss later in this article.
Model accuracy can be degraded due to data drift of the training data or input data. Continued training pipelines detect these by monitoring data drift and model accuracy against the benchmark and automatically re-training the model. Continuous training is an advanced feature of the MLOps pipeline. We may not have to have this at the start of the journey.
Engineering Challenges
- Create a project structure and metadata set which supports the model logic, pre-trained model fetching, and support for various ML frameworks.
- Building CI / CD / CT pipelines crafted to meet the unique ML requirements.
- Integrate data accuracy tests to CI pipelines.
- Integrate feature validation to CI pipelines
- Ensure compatibility between the model training environment and the run time environment via CD.
- Use existing or build a model registry to maintain model versions, metadata, and model artifact.
- Cover the feature definitions, model artifacts, and model serving containers via the CD pipeline.
There are no out-of-the-box solutions for this kind of CI/CD pipeline. However, we can build such a pipeline via well-known CI/ CD tools like.
Source control: Git
CI/CD pipeline: Bit bucket pipelines, Jenkins, AWS CodePipeline, CircleCI
Model packaging: Docker
Model Register: MlFlow
Infrastructure as code: Terraform
Model Serving
Model serving is unique and drastically different from usual software system serving. The following items are not the only ones, but critical characteristics which make it different from the rest of the practices.
Model serialisations
ML models are developed using frameworks such as Tensor Floe, PyTorch, Hugging Face, sci-kit-learn, Keres, Apache MXNet, and many more. These frameworks use their libraries and own serialization formats. Hence, ensuring the model serving container can support the serialisation format is essential.
Due to its popularity among data scientists, Python is the language used by most of these frameworks. However, other languages in the software ecosystem do not have much support for these serialisation formats.
Packaging the model
A model is a binary file serialised in some specific format. The model cannot do much in the production environment and cannot deliver business value. There should be supporting code to the model inference and make it an API.
Integration with business service
Model wrapped into a predication service also not adding the business value. The business value comes when the model is integrated into another business service or functionality that allows that service to make a data-driven decision.
For example, detecting a fraudulent transaction is money saved for both bank, and it’s the customer. Another service owns this business functionality; the predication service is one of its upstream services.
Engineering Challenges
- Supporting various types of serialisation and run times supports via internally manages base images. Another alternative would be bringing open standards like an open neural network exchange (ONNX) format and supporting many frameworks.
- Model and inference logic require various libraries, which have a fragile relationship; figuring out which recipe works for your organisation and managing that in a scalable way is a challenge.
- The business service communicates about ubiquitous transport and data forms like JSON, gRPC over TCP, and HTTP. But the models require specific formats like Matrices. There should be an adapter layer between these two.
- Invoking a predication service is as straightforward as other services; you need input and feature data to do that. The intermediate layer should do these.
Model Monitoring
Data quality monitoring
For traditional web services, we need to monitor the golden metrics, latency, throughput, error rate, and resources. To monitor those matrices, we only need to watch the application execution and runtime environment.
Machine learning models are as good as the quality of the data used to train them.
What we mean by quality is the similarity of numerical characteristics of the trained data and prediction input.
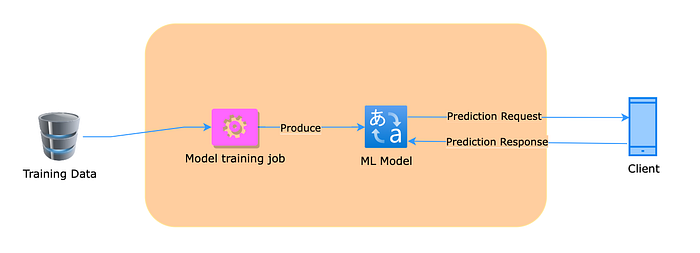
Any difference between the training and prediction request data is identified as a data drift. The MlOps process should monitor it and investigate.
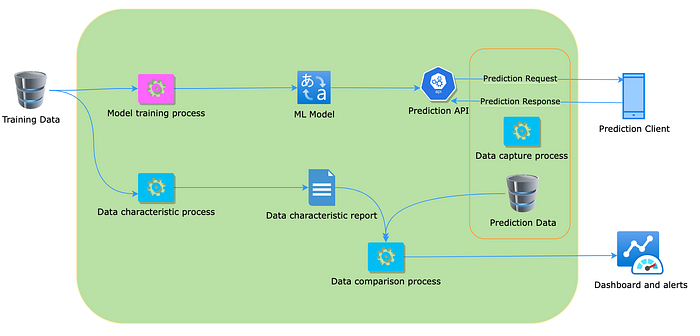
Data characteristic job: This takes the training data set and creates a set of numerical characteristics from it, which can be compared with the prediction input data.
Data capture process: This process captures the prediction inputs and outputs and delivers them to the prediction database.
Comparison job: This process compares training and prediction data characteristics and reports any data drift.
Model performance monitoring
The other monitoring aspect we will discuss here is model accuracy monitoring. We must compare the prediction output with the ground truth in this case. Ground truth is the reality we want to model with our supervised machine-learning algorithm.
That is machine learning-specific terminology. To make it easy to understand, look at the example below, which explains how to formulate the ground truth for a shopping cart application that suggests related product items based on customer profiles.
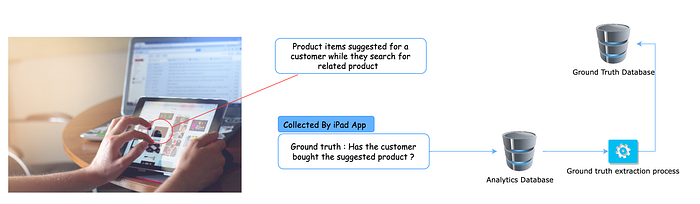
How does this fit into the model accuracy monitoring? Ultimately accuracy of the model is how close its prediction is to real-world actions. In our shopping cart example, if the customer bought the suggested item or clicked the item to see the item description in reviews, that is an accurate prediction.
If not, then that prediction is not closely mimic real-world actions.
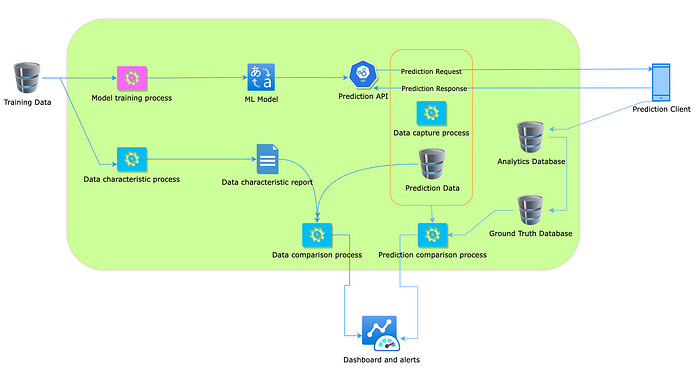
The above diagram completes the full picture of data and model performance monitoring by adding the ground truth formulation process.
Once the ground truth is in the data source, the prediction comparison process can compare the prediction results with the ground truth and creation inputs for the dashboards.
Engineering challenges
- Defining the model monitoring process and consistently running those model training, data characteristic jobs, data comparison, and prediction comparison jobs to support the machine learning practitioners is not trivial. These are usually run via Apache Spark clusters, and due to unorganised python dependency management, keeping a consistent, sustained set of runtimes is hard.
- Not all client applications are built with the correct set of analytics events to derive ground truth; you may need to sell this value to the business services teams and convince them to integrate analytics into their applications.
- Analytics events are camouflaged beasts; they come in large numbers. Building data pipelines and purifying them is much larger engineering work and requires considerable time and effort.
- Building dashboards are trivial these days with sophisticated monitoring tools. However, maintaining those with business changes and technical changes is challenging for MLOps teams.
- After all, these efforts are to serve business needs, and monitoring the cost of all these components is another challenge.
Final thoughts
In this article, I tried to go through the key operational aspects of Machine Learning and associated software engineering challenges, as I understood. I am not an expert in this subject but a humble beginner. This article aims to articulate and share the learnings and challenges I found during my learning process.
I can conclusively say that Machine Learning is coming to the maturity level where large to medium size companies need more data engineers/software engineers in the Machine Learning space who know how to run models in a production environment.
